A visual tutorial of Inversion Sampling
2020-06-19
Efficient inversion sampling explained with Python.
Inversion sampling is a simple and very efficient way to generate samples of some arbitrary probability function. Unlike rejection sampling, there are no rejected samples, and by leveraing common python libraries, we don’t even have to do any tricky integrals or function inversion.
between 0 and 1. It just happens this does integrate to 1, what luck! Now, the CDF (cumulative distribution function) is the integral of the probability density function (what you see above), integrated from the lower bound - in our case the bounds are 0 to 1, so the CDF is
Let’s visualise the PDF and the CDF quickly:
import numpy as np
import matplotlib.pyplot as plt
def pdf(x):
return 2 * x
def cdf(x):
return x**2
xs = np.linspace(0, 1, 1000)
ps = pdf(xs)
cdfs = cdf(xs)
fig, axes = plt.subplots(ncols=2)
axes[0].plot(xs, ps, label="PDF")
axes[0].fill_between(xs, ps, 0, alpha=0.2)
axes[1].plot(xs, cdfs, label="CDF")
axes[1].fill_between(xs, cdfs, 0, alpha=0.2)
axes[0].set_xlabel("x"), axes[1].set_xlabel("x")
axes[0].legend(), axes[1].legend();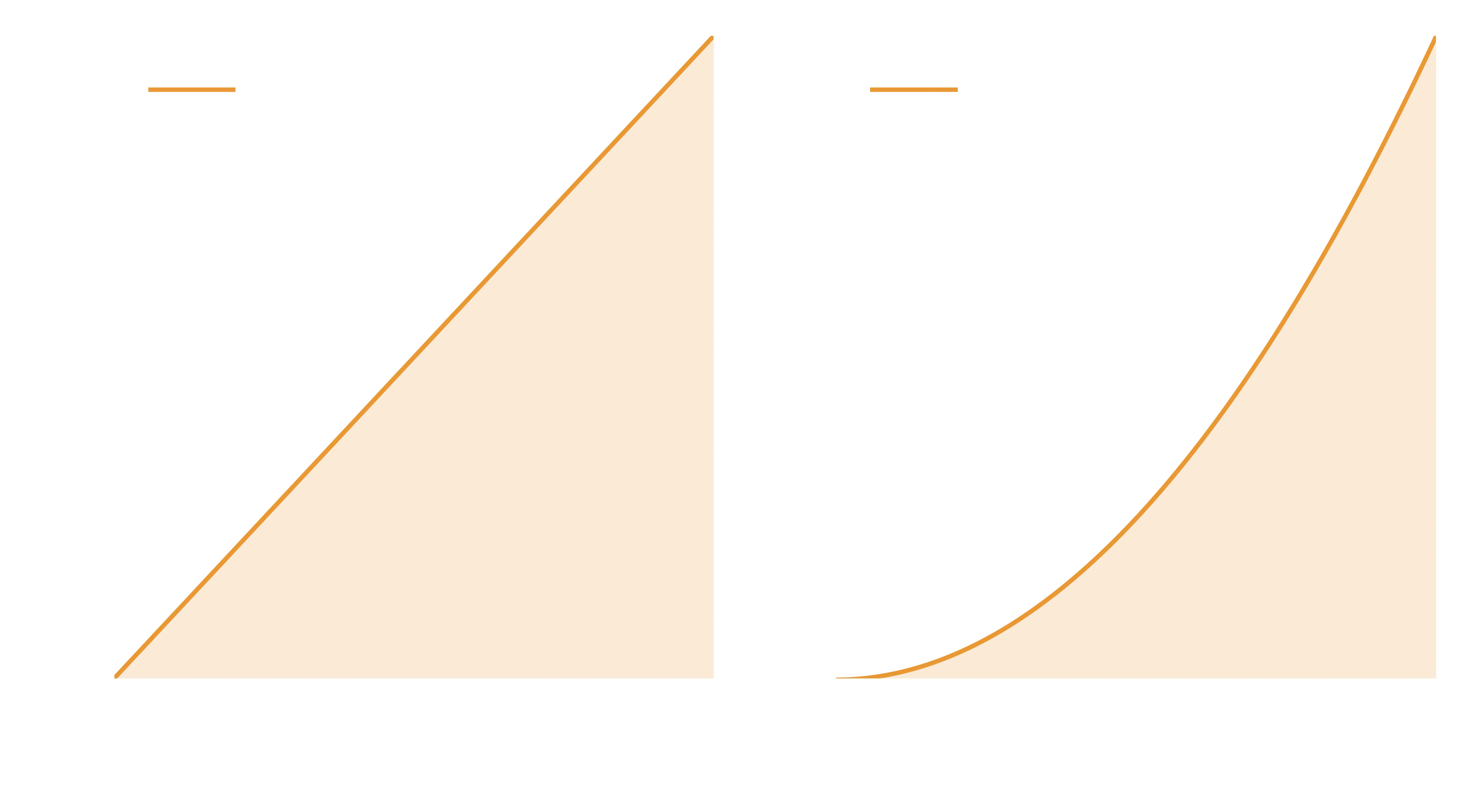
So in our case, the CDF looks pretty similar to the PDF, obviously this won’t be the case if we picked something other than a simple polynomial, but you get the idea. The property that we are making use of is that the CDF will - by definition - go from 0 to 1 for any PDF. So for inversion sampling, we follow a simple procedure:
- Pick a number (our CDF value) between 0 and 1
- Figure out what value gives that CDF
- Return that value as our sample.
That’s it!
The most common cause of confusion is “Why are we uniformly sampling the CDF?” Think about it like this - between CDF values 0.2 and 0.4, there is 20% of the probability area, right? And if you uniformly sample between 0 and 1, you get between 0.2 and 0.4 20% of the time.
So let’s write this up for our function above, and then we’ll generalise to any function and remove the math.
def inverse_cdf(cdf):
return np.sqrt(cdf) # cdf = x**2, so x = sqrt(cdf)
def sample(n=1):
u = np.random.random(size=n)
return inverse_cdf(u)
samples = sample(n=100000)
plt.plot(xs, ps, label="PDF")
plt.fill_between(xs, ps, 0, alpha=0.2)
plt.hist(samples, density=True, alpha=0.3, label="Samples")
plt.legend(), plt.xlabel("x");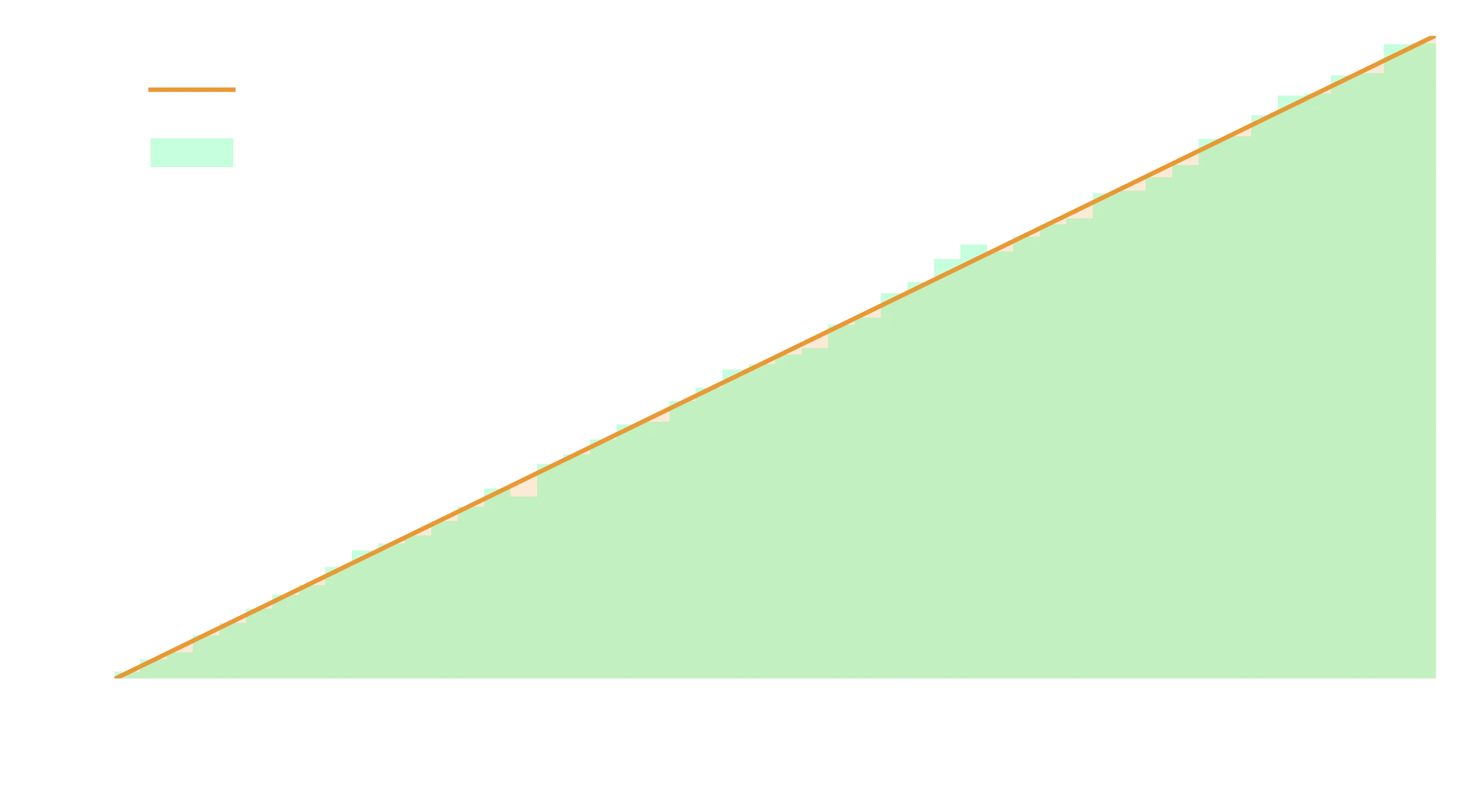
Great, so this is obviously working well, the sample distribution closely follows the input PDF. So lets generalise this to be any function. We can use simple numeric integration to remove the requirement for us to be able to analytically integrate and then invert the PDF.
xs = np.linspace(0, 6.06948, 1000)
pdfs = ((1 + np.cos(xs)) / (1.5 * xs + 3))
plt.plot(xs, pdfs, label="PDF")
plt.fill_between(xs, pdfs, 0, alpha=0.2)
plt.xlabel("x"), plt.legend();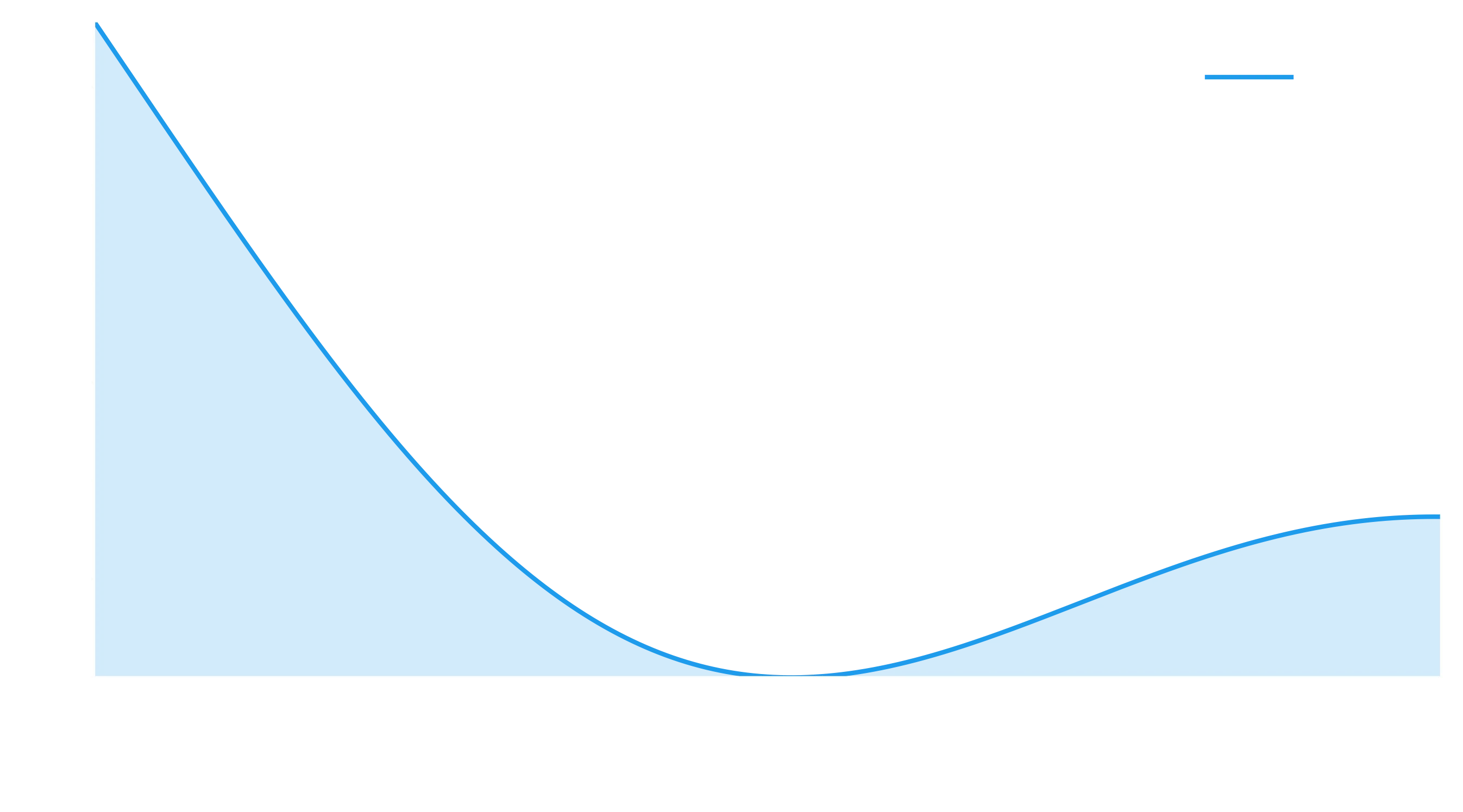
Now lets determine the CDF, invert it, and return an interpolator we can use to sample it:
Let’s check it works by comparing the histogram of samples to the function:
plt.plot(xs, pdfs, label="PDF")
plt.fill_between(xs, pdfs, 0, alpha=0.2)
plt.hist(samples_2, density=True, alpha=0.3, label="Samples")
plt.legend(), plt.xlabel("x");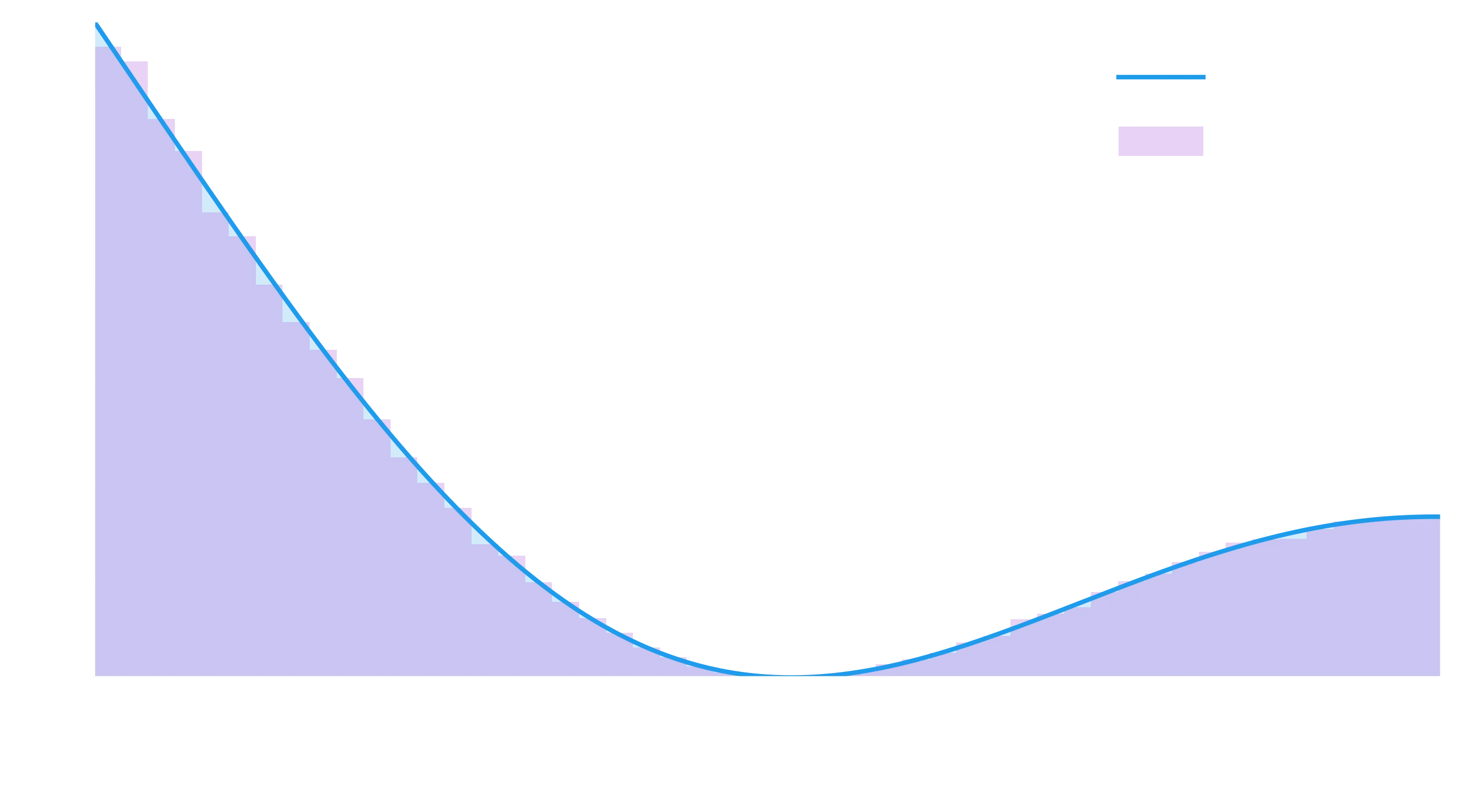
Beautiful. Now to try and tie it all together, here is one final, more complicated plot, showing the sampling of the CDF (on the top y axis), to figuring out what value it corresponds to, to where those samples lie in the PDF on the bottom.
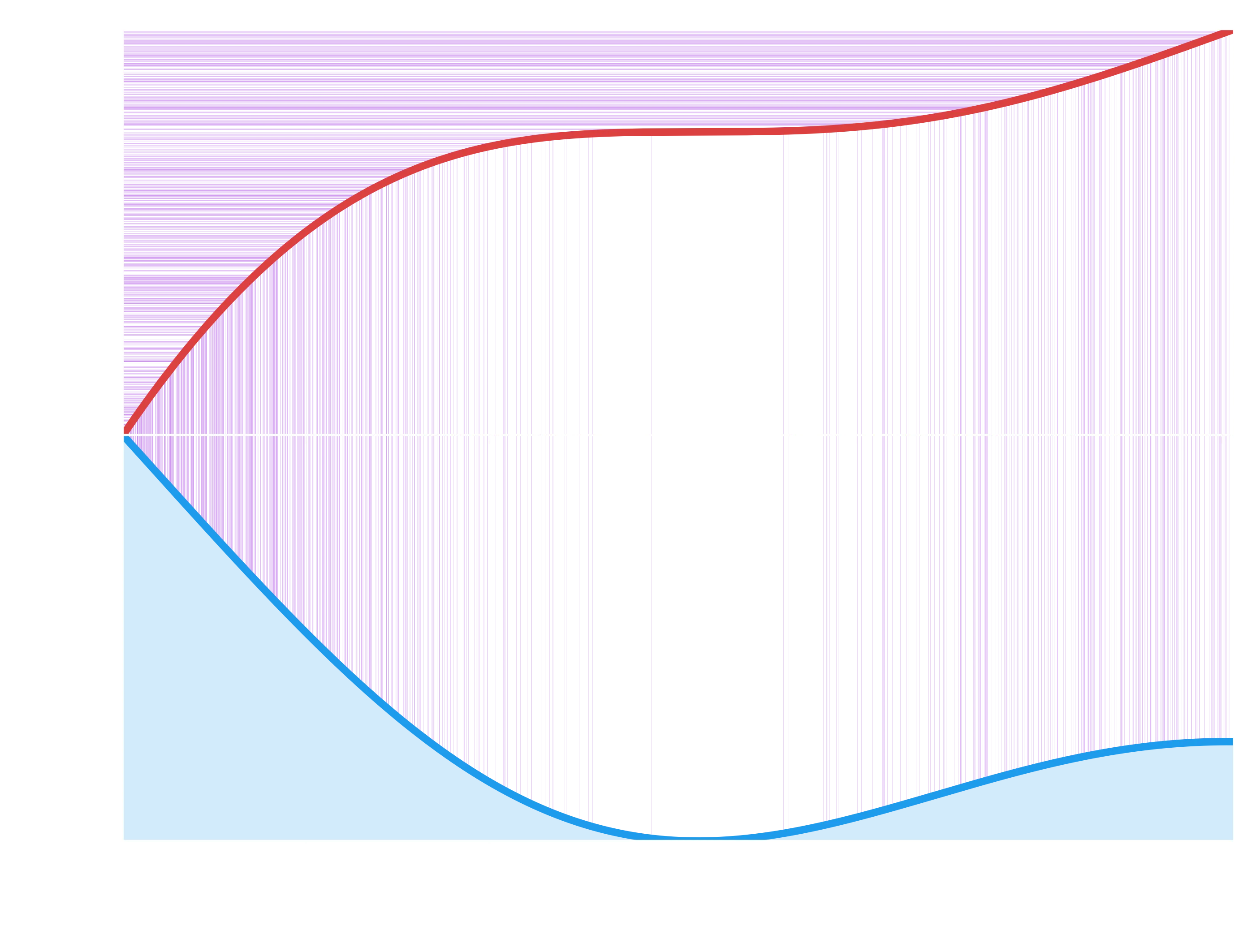
So you can see - hopefully fairly clearly - how our uniform sampling on the CDF, after being traced horizontally to the CDF and then vertically down to the value, gives us samples which are distributed according to the underlying PDF.
For your convenience, here’s the code in one block:
import numpy as np
import matplotlib.pyplot as plt
def pdf(x):
return 2 * x
def cdf(x):
return x**2
xs = np.linspace(0, 1, 1000)
ps = pdf(xs)
cdfs = cdf(xs)
fig, axes = plt.subplots(ncols=2)
axes[0].plot(xs, ps, label="PDF")
axes[0].fill_between(xs, ps, 0, alpha=0.2)
axes[1].plot(xs, cdfs, label="CDF")
axes[1].fill_between(xs, cdfs, 0, alpha=0.2)
axes[0].set_xlabel("x"), axes[1].set_xlabel("x")
axes[0].legend(), axes[1].legend();
def inverse_cdf(cdf):
return np.sqrt(cdf) # cdf = x**2, so x = sqrt(cdf)
def sample(n=1):
u = np.random.random(size=n)
return inverse_cdf(u)
samples = sample(n=100000)
plt.plot(xs, ps, label="PDF")
plt.fill_between(xs, ps, 0, alpha=0.2)
plt.hist(samples, density=True, alpha=0.3, label="Samples")
plt.legend(), plt.xlabel("x");
xs = np.linspace(0, 6.06948, 1000)
pdfs = ((1 + np.cos(xs)) / (1.5 * xs + 3))
plt.plot(xs, pdfs, label="PDF")
plt.fill_between(xs, pdfs, 0, alpha=0.2)
plt.xlabel("x"), plt.legend();
from scipy.interpolate import interp1d
from scipy.integrate import cumtrapz
def get_inverted_cdf(xs, pdfs):
cdfs = cumtrapz(pdfs, x=xs) # Get the CDF using a very fast trapz rule
cdfs = cdfs / cdfs.max() # Ensure its normalised, to cater for unnormalised PDFs
cdfs = np.insert(cdfs, 0, 0) # Add the 0 area to start of the CDF array
return interp1d(cdfs, xs, kind="linear") # return interpolation from cdf -> x
def sample_fn(fn, n=1):
return fn(np.random.random(size=n))
fn = get_inverted_cdf(xs, pdfs)
samples_2 = sample_fn(fn, n=100000)
plt.plot(xs, pdfs, label="PDF")
plt.fill_between(xs, pdfs, 0, alpha=0.2)
plt.hist(samples_2, density=True, alpha=0.3, label="Samples")
plt.legend(), plt.xlabel("x");