Royal Road AB Ad Test
2024-01-09
What are the best sort of ads to run on Royal Road? Meme ads.
If you don’t know what A/B tests are, feel free to check out this tutorial, but to boil it down a sentence: “Do a bunch of things at once and see which is better.”
So yeah, I ran 9 ads in parallel. The plan was to run 10, but my “Kindle” word got covered by the “User Ad” rectangle in the overlay, so the ad wasn’t approved, and I decided to just forgo it rather than run it at a different time.
Now, the big caveat here is that my story is on Kindle, and clicking outside RR won’t be as effective as promoting another RR story.
TL;DR: Meme ads are king. Ridiculously so.
The Ads
I wanted to go for a few different categories: text-heavy ads showing story tags, more formal title+cover ads, meme-adjacent ads (like the Bestest Brother one), and full meme ads (the final one).

Now if you just want to know which ad was best, ad 9, the one in the bottom right corner, destroyed everything else. But if you want to see how the click-throughs compare and changed over time, continue reading. To make things easier, here is each campaign labelled:

Performance over time
As typical with RR, we see declining results as we churn through the entire reader base and the target that would have clicked have already done so. This is most prominent with the meme ads, and we can see a drop from an initial click-through rate (CTR) of 2.8% down to 1.7%. I copied and pasted the table out of the RR ad centre eight times over the campaign. The plan was to do it more, but I… forgot. Oops.
Anyway, below you can see both the CTR evolution and the uncertainty in that mean CTR.
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
colors = {
1: "#dc5a5a",
2: "#80b7be",
3: "#45b191",
4: "#865bab",
5: "#d48ebb",
6: "#ffd76e",
7: "#a7e75f",
8: "#c9ac9a",
9: "#fcf6d0",
}
df = pd.read_json("data.json", orient="records", convert_dates=["Time"])
df = df.sort_values(["Ad", "Time"])
df["CTR"] = df["Clicks"] / df["Views"]
df["CTR_err"] = np.sqrt(df["CTR"] * (1 - df["CTR"]) / df["Views"])
fig, ax = plt.subplots()
for ad, df_ad in df.groupby("Ad"):
df_ad = df_ad.sort_values("Time")
ax.plot(df_ad["Time"], df_ad["CTR"] * 100, color=colors[ad])
ax.set_ylabel("Total CTR (%)")
ax.set_xlabel("Time")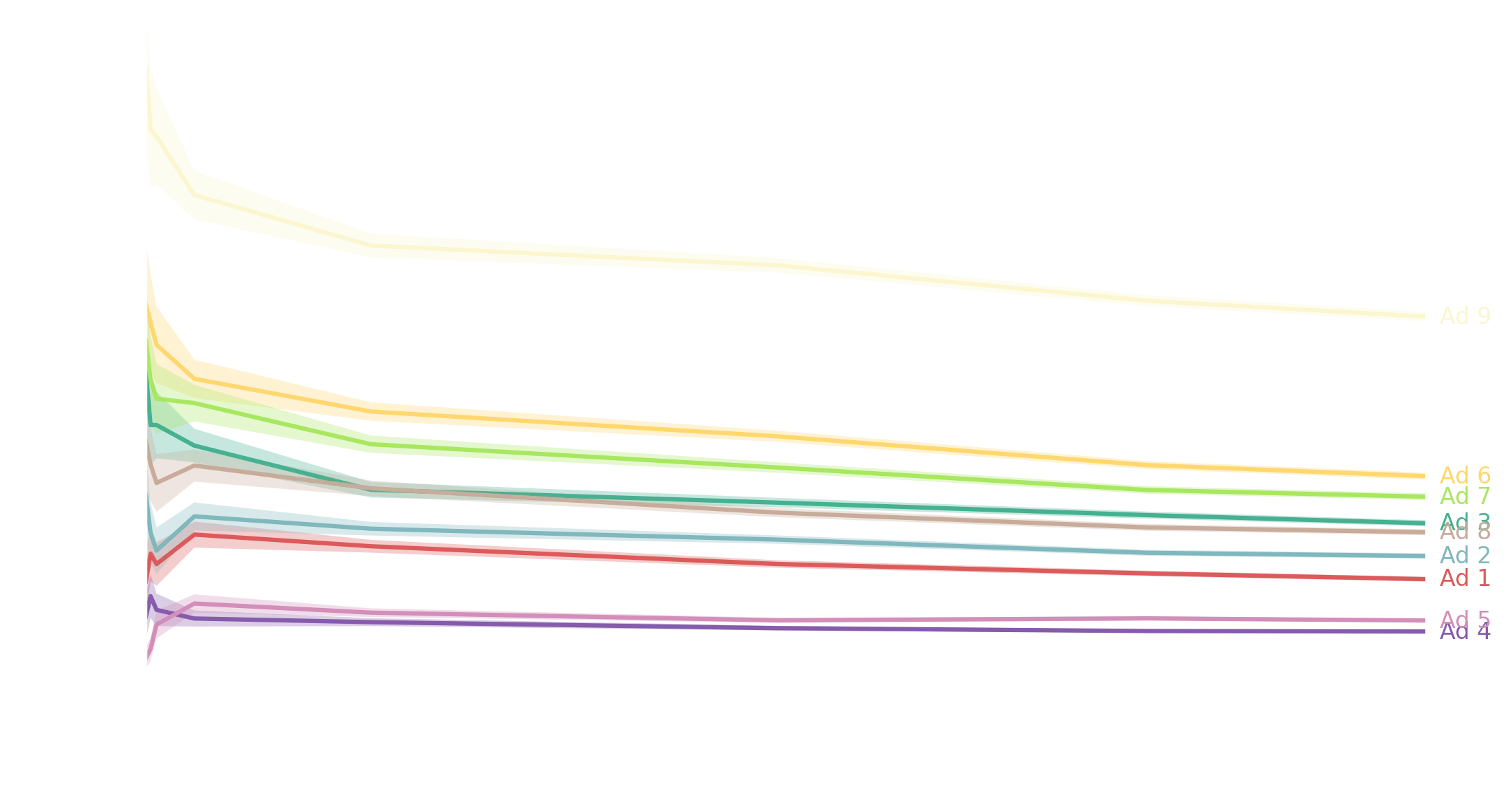
To me this is pretty clear evidence that you should never spend more than the minimum $50USD and should instead trial ad permutations. Note that what you’re seeing above is the total CTR. The fact that the meme ad dropped from 2.8% to 1.6% means that the instantaneous CTR at the end must be far lower than 1.6% to get 1.6% as the final average (for the meme ad, the final CTR over the last 5 days is around 1.3%).
If I had better time resolution, I’d plot this. Ah well.
For a final leaderboard:
df_final = df.loc[df["Time"] == df["Time"].max(), ["Ad", "CTR"]]
fig, ax = plt.subplots(figsize=(8, 8))
ax.barh(
10 - df_final["Ad"],
df_final["CTR"] * 100,
color=[colors[ad] for ad in df_final["Ad"]],
)
ax.set_xlabel("Final CTR (%)")
Anyway, this took more time and money than I wanted, so here’s hoping this is useful for someone!
For your convenience, here’s the code in one block:
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
colors = {
1: "#dc5a5a",
2: "#80b7be",
3: "#45b191",
4: "#865bab",
5: "#d48ebb",
6: "#ffd76e",
7: "#a7e75f",
8: "#c9ac9a",
9: "#fcf6d0",
}
df = pd.read_json("data.json", orient="records", convert_dates=["Time"])
df = df.sort_values(["Ad", "Time"])
df["CTR"] = df["Clicks"] / df["Views"]
df["CTR_err"] = np.sqrt(df["CTR"] * (1 - df["CTR"]) / df["Views"])
fig, ax = plt.subplots()
for ad, df_ad in df.groupby("Ad"):
df_ad = df_ad.sort_values("Time")
ax.plot(df_ad["Time"], df_ad["CTR"] * 100, color=colors[ad])
ax.set_ylabel("Total CTR (%)")
ax.set_xlabel("Time")
df_final = df.loc[df["Time"] == df["Time"].max(), ["Ad", "CTR"]]
fig, ax = plt.subplots(figsize=(8, 8))
ax.barh(
10 - df_final["Ad"],
df_final["CTR"] * 100,
color=[colors[ad] for ad in df_final["Ad"]],
)
ax.set_xlabel("Final CTR (%)")